Los sistemas de gestión de bases de datos (en inglés database management system, abreviado DBMS) son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que la utilizan.
El propósito general de los sistemas de gestión de bases de datos es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante para una organización.
Un gestor de almacenamiento es un módulo de programa que proporciona la interfaz entre los datos de bajo nivel almacenados en la BD y los programas de aplicación y las consultas remitidas al sistema.







Jesús Ramos
Nelson Guerra
Víctor Matos
William Milano
Wilson Herrera
Componentes del gestor de
almacenamiento
- Gestor de autorizaciones e integridad.
- Gestor de transacciones.
- Gestor de archivos.
- Gestor de la memoria intermedia.

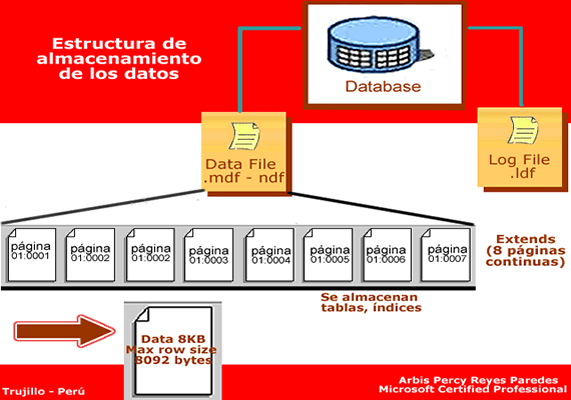
Estructura de Almacenamiento
- Archivos de datos.
- Diccionario de datos.
- Índices.
Tipos de entonación
Los sistemas manejadores de base de datos trabajan sobre
una plataforma de hardware y en estrecha
interacción con el sistema de operación sobre el cual funciona la plataforma.
En primera instancia, hay aspectos del HW y del sistema
de operación que afectan el rendimiento en la base de datos. Estos aspectos
son:
- Del S.O.: scheduling de procesos, prioridad de los procesos, tamaño del búfer.
- Del HW: como ubicar (allocate) los discos, la memoria RAM y los procesadores para uso del DBMS.
Índice y Clúster
El índice de una base de datos es
una estructura de datos que mejora la velocidad de las operaciones,
permitiendo un rápido acceso a los registros de una tabla en una base de
datos. Al aumentar drásticamente la velocidad de acceso, se suelen usar sobre
aquellos campos sobre los cuales se hacen frecuentes búsquedas.
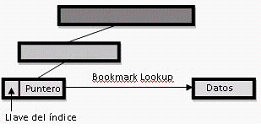
Estructura interna de un índice

En un índice non-clustered, la clave por la que buscamos tiene un puntero a la página de datos donde se encuentra el registro. Mientras que en índice clustered, la leaf level es la pagina de datos!.
Búsqueda por clustered index

Búsqueda por non-clustered index
Tablespace
Una base de datos se
divide en unidades lógicas denominadas TABLESPACES. Un tablespace no es un fichero físico
en el disco, simplemente es el nombre que tiene un conjunto de propiedades de
almacenamiento que se aplican a los objetos (tablas, secuencias…) que se van a
crear en la base de datos bajo el tablespace indicado (tablas, secuencias…).
Datafile
Un datafile es la representación física de un tablespace. Son los "ficheros
de datos" donde se almacena la información físicamente.
Un datafile está asociado a un
solo tablespace y, a su vez, un tablespace está asociado a
uno o varios datafiles. Es decir, la relación lógica entre tablespaces y datafiles es de 1-N, maestro-detalle.
Segmentos Especiales
Un segment es aquel espacio reservado por la base de datos, dentro de
un datafile,
para ser utilizado por un solo objeto.
Se puede decir que, un segmento es a un objeto de base de
datos, lo que un datafile a un tablespace: el segmento es la representación física del objeto en
base de datos (el objeto no es más que una definición lógica).
.jpg)
En Resumen
El propósito general de los sistemas de gestión de base de datos es el de manejar de manera clara, sencilla y ordenada un conjunto de datos que posteriormente se convertirán en información relevante, para un buen manejo de datos.
En el entorno informático, la gestión de bases de datos ha evolucionado desde ser una aplicación más disponible para los computadores, a ocupar un lugar fundamental en los sistemas de información. En la actualidad, un sistema de información será más valioso cuanto de mayor calidad sea la base de datos que lo soporta, la cual resulta a su vez un componente fundamental del mismo, de tal forma que puede llegarse a afirmar que es imposible la existencia de un sistema de información sin una base de datos, que cumple la función de "memoria", en todas sus acepciones posibles, del sistema.
Las bases de datos almacenan, como su nombre dice, datos. Estos datos son representaciones de sucesos y objetos, a diferente nivel, existentes en el mundo real: en su conjunto, representan algún tipo de entidad existente. En el mundo real se tiene percepción sobre las entidades u objetos y sobre los atributos de esos objetos; en el mundo de los datos, hay registros de eventos y datos de eventos. Además, en ambos escenarios se puede incluso distinguir una tercera faceta: aquella que comprende las definiciones de las entidades externas, o bien las definiciones de los registros y de los datos.
La transferencia entre las entidades del mundo real, y sus características, y los registros contenidos en una base de datos, correspondientes a esas entidades, se alcanza tras un proceso lógico de abstracción, conjunto de tareas que suelen englobarse bajo el título de diseño de bases de datos. Sin embargo, es necesario definir, en primer lugar, qué es una base de datos, independientemente de su diseño y/o su orientación.
INGENIERÍA EN INFORMÁTICA, TRAYECTO IV, SECCIÓN "1".
Administración de Base de Datos, Equipo 4.
Integrantes:
Amarilys Martínez Jesús Ramos
Nelson Guerra
Víctor Matos
William Milano
Wilson Herrera

